
Scalability Under Scrutiny: Will the Technology Crumble Under Growth?
A technical deep-dive into evaluating startup scalability: what to check, what to ask, and when to walk away

The High Stakes of Scaling
When a product finally hits product-market fit, especially with viral growth, it’s exhilarating. What’s there not to love? User base growing, traffic growing, features growing, popularity soaring.
Fantastic. But there’s also the wonderful problem of scaling that pops up. This is precisely when technical foundations are tested most severely. Remember Vine? Despite its rapid user growth and innovative short-form video concept, Vine ultimately could not meet the demands and competitive pressure from its parent company, Twitter, effectively leading to its shutdown in 2017. It’s a stark example of how even popular platforms can falter when they can't overcome technical or strategic hurdles.
Inability to scale is a core business risk. Scalability failures aren't just inconvenient; they cost money, destroy user trust, halt innovation, and can cripple a business at its most critical phase. You’ve probably seen websites go down when they get “hugged by death”. You wouldn’t want that to happen to the company you’re leading/advising/investing into. Right?
Most founders and engineering leaders that I have met claim their system "scales infinitely." Outsiders can't verify this. I take a rigorous, skeptical approach to assessing scalability – not just asking “can it scale?”, but how, at what cost, and how robust.
Below, I outline the key areas I examine when assessing scalability, beyond surface-level checks. It will help you understand if the underlying tech is a foundation for growth or a ticking time bomb. I aim to get you a no-nonsense look at evaluating infrastructure, databases, and application architecture, focusing on tangible indicators of future scalability and the risks of ignoring them.
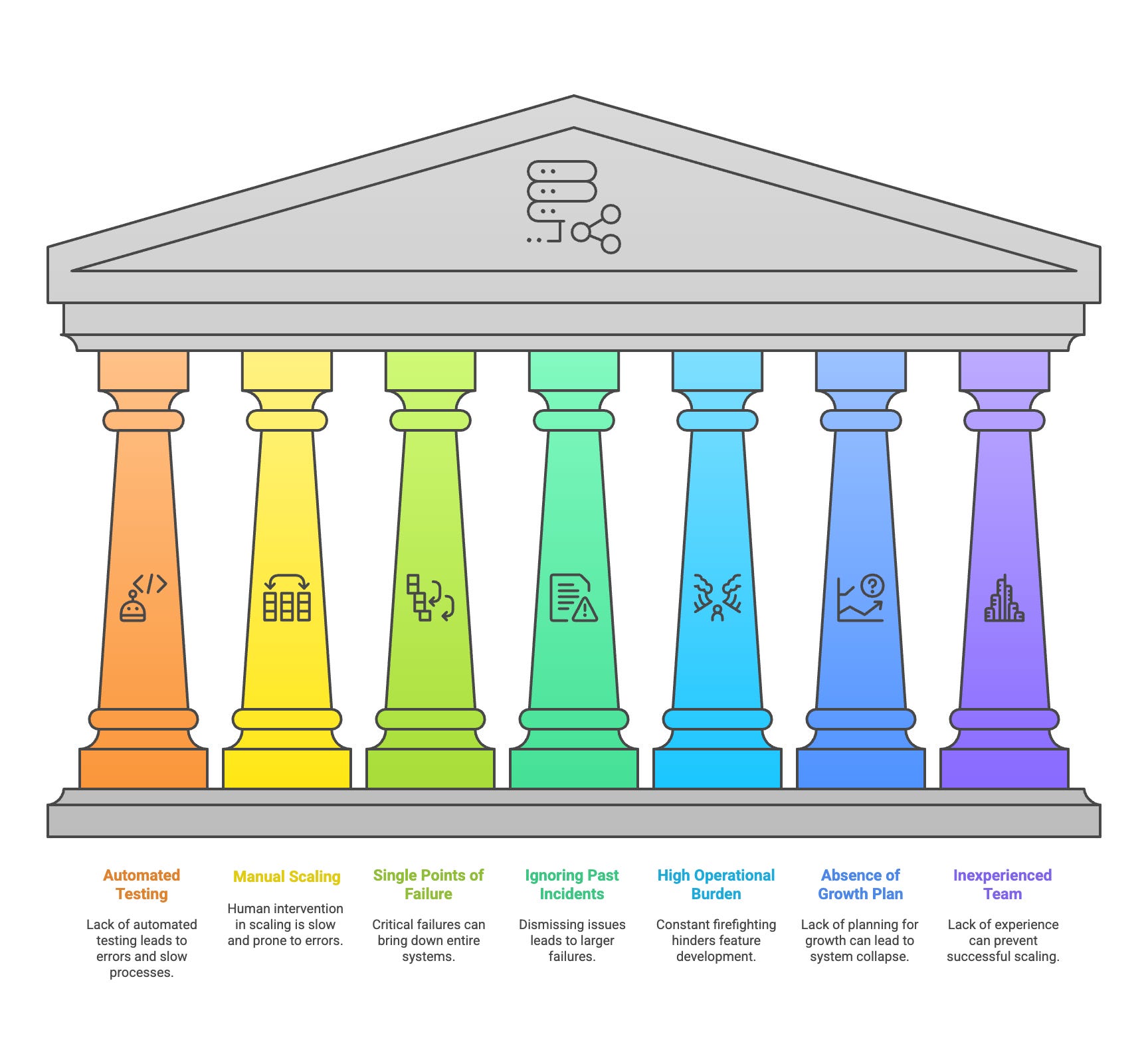
Quick Red Flags
I’ve identified a few common warning signs that you should look out for:
No automated testing. It’s a problem, as manual testing is error-prone and tends to be slow. Manual testing should complement automated testing, not be the only available testing. Also, performance or load testing is important. "It works on my machine" or "it handles 100 users" isn't enough.
Manual scaling – if responding to surge in traffic requires human intervention, it’s a problem. Humans are slow and error-prone under pressure. You want something like elastic scaling, where the infrastructure scales up (i.e. new servers are automatically provisioned) as the traffic surges. And when the traffic subdues, the extra infrastructure is decommissioned.
Single points of failure (SPOF) are critical, both on the system side and on the team side. Any component where failure brings down the whole system has to be eliminated. The same is relevant for the engineering team – knowledge should be shared, documented and maintained. The exit of a single important person (even a founder) must not be a seismic event.
Ignoring past incidents signals low-learning engineering culture. Dismissing production issues as “one-offs” invites larger, catastrophic failures down the line. A solid operational culture requires looking at the systems in place (both technological and human) and their flaws, rather than just the symptoms.
High operational burden or toil is the bane of engineering teams. When the team is constantly firefighting instead of building features, the system is fragile under load. It requires systematic investment. Building new features in this case is useless - no one can use features of an app that goes down every day.
Absence of a plan for growth signals that there’s no thought given to how the system will grow. Surge in popularity can bring 3 to 5 orders of more load or data, and the human-technological systems have to be prepared for such an event.
Inexperienced team is the last sign – if the team hasn’t successfully scaled similar architectures before, it’s unlikely they’ll do it now. The leadership has to bring someone experienced right away to close the knowledge gap and bring others up.
Conversation starters to dig out these hidden issues:
Show me your last three incident postmortems.
What happens when your database goes down?
How do you deploy code during peak traffic?
What's your plan for 100x user growth?
Who's your most experienced engineer with scaled knowledge?
At face value these issues are manageable. But usually they have an underlying problem, which if not solved will trigger the cascading failures that killed Vine: turning a growth opportunity into a business-ending crisis.
How I think about Scalability in Practical Terms
Scalability isn't just "add more servers." Scalability is the system's ability to handle increasing load. It’s basically the opposite of “hug of death” - it’s the ability to survive the hug. But survival at any cost isn’t the goal. An expensive, barely-hanging-on system is still better than failure, but not by much. The goal is to have a healthy business with systems that scale efficiently, reliably, and cost-effectively.
Systems that require significant architectural changes or performance degradation are not scalable; they’re a liability.
To understand load, I think about it in three dimensions:
User volume: this is not just total registered users, but concurrent users and different user behavior patterns (heavy v.s. light users).
Data volume: growth of the database, stored files, logs, events. As the business acquires more users and more product usage, it’s key to think about the performance implications of data growth.
Transaction/throughput load: number of API calls or requests per second, orders processed per minute, data points ingested per hour.
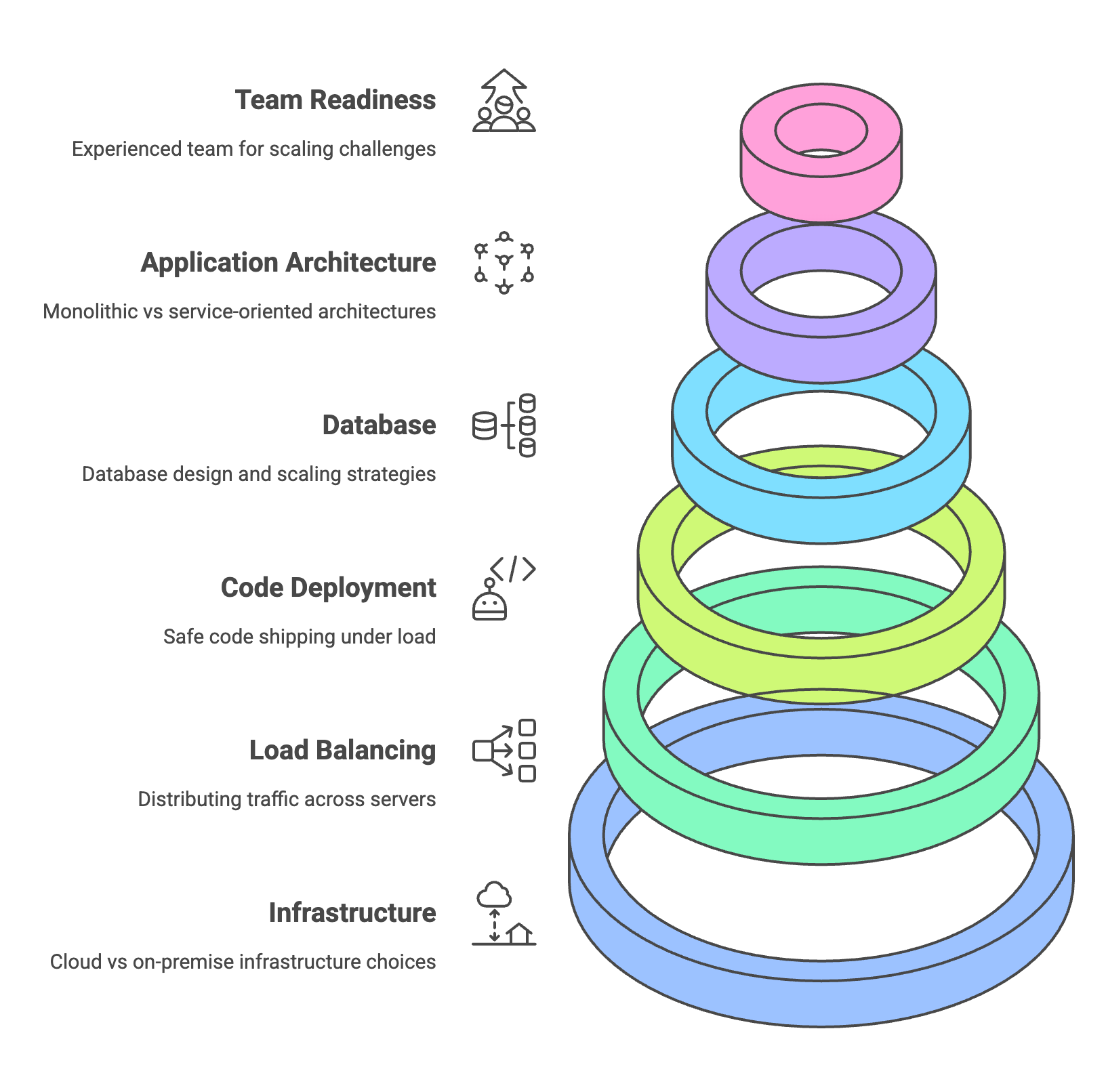
Where I Dig Deeper: The Foundations
In my assessment, I start with the principles and assumptions under which the system was built. For example, a popular blog is engineered for heavy read-load – new content is occasionally published, but the same content is served million of times per day. Also, I assess the traffic patterns too, because the traffic volatility assumption is baked into the foundations.
Cloud v.s. On-prem
In general, systems can run in two infrastructure types: in the cloud or managed/on-premise infrastructure. Both have their pros and cons. While the elastic features of cloud providers are amazing, they also come at a significant premium.
The alternative is on-premise or hybrid infrastructure. This means that the team owns the hardware that it runs its systems on. This could mean literal server racks in a basement or equipment hosted in a third-party data center. On-prem infra requires significant in-house expertise, capital expenditure, and manual processes to scale. I assess the team’s track record: with cloud providers you pay for that reliability, but the reliability of on-prem infra requires expertise. That expertise is essential, yet I have found that it varies wildly between companies.
Load balancing
Load balancing is essential to scaling, because it’s the method of distributing network traffic across a pool of servers. It’s the lowest hanging fruit for scaling, so I have found it as a good indicator about the team’s readiness.
As the product adoption scales, more resources (e.g. servers) will be added to handle the new traffic. Load balancers make sure all traffic is equally spread through the available infrastructure.
Additionally, traffic distribution removes single points of failure, effectively mitigating the “hug of death” I mentioned before.
Shipping Code Safely
Observability is a combo of monitoring, logging, alerting and telemetry. Observability allows the engineering team to detect the incoming traffic/load. With meaningful metrics (e.g. request rates, error rates, latency, resource utilization), the engineering team can preempt scaling issues. Lack of observability is a major scaling liability.
Shipping code under load is extremely important to scaling. The deployment process must be orthogonal to infrastructure scaling. In other words, engineers must be able to deploy new code even when the systems are under load.
The code must be tested, so deployments can be automated, i.e. via Continuous Integration (CI) and Delivery (CD) pipelines. Manual deployments under stress lead to mistakes (and downtime), so it’s best practice to remove humans from the process.
Operational posture is essential for scale. As the team adapts the infrastructure for scale it leads to infrastructure sprawl. More servers, more services, more fit-for-purpose applications. The team must have the right observability, alerting and muscle memory to efficiently handle regressions. Up-to-date runbooks are essential to operating systems under pressure.
Lastly, the infra cost model. As the infrastructure scales, the team must have a grip on how the costs scale. Linearly? Sub-linearly? Exponentially? Online you can find plenty of horror stories about runaway cloud infra costs bankrupting companies.
The Database: Where Most Scaleups Break
In my work with different scaleups I’ve noticed a pattern: the database was a bottleneck. Databases are the workhorse of many early-stage companies, so with traffic surges it’s the first piece to show cracks. A good database design will prolong the slowdown, but a suboptimal design will cripple the system the moment growth starts. This is where the 'money down the drain' scenario becomes real - I've watched marketing spend get completely wasted when databases couldn't handle the incoming traffic.
The Right Database For the Problem?
Choosing the right database is tricky. Plenty of options to choose from, from the typical relational databases, to document databases (i.e. NoSQL), to specialized time series or search-optimized databases. Yet, the scaling ability of an early-stage product is a function of the database(s) design and the underlying technology.
Each database type has its own scaling challenges and trade-offs. The key is matching the technology to your data patterns and growth trajectory. When I see a mismatch - like trying to scale a social network using a relational database instead of a graph database - it's a red flag.
Choosing the right database type is crucial to the scaling success of the product, especially in those early stages. Here, I trust my gut. When I see a mismatched database choice I dig in to uncover the red flag, if any.
Schema Design & Scaling Strategies
Schema design and indexing are important scaling topics. The way the schema and the indices are set up to support the heaviest queries will affect the scaling. For example, efficient indexes help with fast retrieval of data on large datasets (e.g. think about using the index of a book versus scanning page by page to find something in a book).
Battle-tested database scaling strategies that you should look for:
Read replicas, i.e. multiple replicas for reading from and one main replica to write to, with proper read-after-write consistency patterns. It eliminates the read bottleneck, as it spreads the load from applications reading data. It’s a tried-and-tested scaling strategy – one scaleup I worked at served 10 million monthly active users just with this strategy.
Sharding and partitioning are common scaling strategies, which involve splitting the database tables/collections based on a sharding key(s). It’s a tad more complicated pattern, as it requires good thinking before choosing a sharding key.
Caching is popular, but I’ve found that in practice people do it poorly. Lots of frameworks/tooling make caching easy, but teams’ cache invalidation strategies are suboptimal. I have seen a team being forced to allocate four engineers to clean up a caching mess for 6 months. All due to bad caching decisions made years ago. In one team I worked at, we had to completely rethink caching which led to a few months of caching configuration rewrite.
There are other aspects to databases I consider, such as data lifecycle (e.g. archival or data purging), or concurrency and isolation. But those are a bit more advanced topics and tend to be relevant for more mature startups.
Application Architecture: The Code's Resilience
With infrastructure assessed, I examine the application architecture.
In my experience, finding the application’s architecture as a bottleneck is tricky. A suboptimal architecture allows for lots of scale. Yet, the wrong architecture will severely damage the app’s ability to scale. Therefore engineering teams always find it difficult to pinpoint the scaling issues on the architecture, as they’re more difficult to measure (e.g. when compared to other components).
Commonly, there are two types of architecture: monolithic and service-oriented. As a high-level observer of the field, you don’t need to get into the weeds of the different subtype of architectures, just knowing these two is sufficient.
Monolithic architectures can become a scaling bottleneck if components can't be scaled independently. It can suffer from shared resources or tight coupling between modules. Not all modules scale the same way, i.e. with an app going viral the landing and registration pages will take a massive hit compared to the in-app messaging system. The monolith’s inability to scale out modules separately can be a headache for the engineering team.
On the other hand, services offer independent scaling, but introduce complexity. Lots of it. Some examples are service-to-service communication, data consistency, distributed tracing, and more. A team that is investing into services needs an overarching vision and principles in place, otherwise they end up in Uber’s 1300+ microservices land.
Team Readiness for Scale
The most elegant architecture won't scale reliably if the team isn't capable of building, deploying, and operating the system under pressure. Scaling isn't just code; it's people, processes and discipline.
Startups tend to employ younger folks, but I don’t care about age. I care about the experience. I avoid the ageism trap: age doesn’t guarantee experience or expertise. I identify whether the core engineering leadership and senior technical staff have experienced individuals who have worked on scaled systems. The "scar tissue" from past scale-ups teaches them the non-obvious pitfalls and operational rigor that less-experienced folks lack.
Digging into the engineering leadership further: the top engineering person (e.g. CTO). Their credibility must be good. Sure, everyone’s done missteps, but as long as they haven’t done a Wirecard-shaped drama – acceptable! More important: can they articulate specific bottlenecks? Do they know their database connection pool limits, memory ceilings, and network throughput constraints? Understanding where the scaling bottlenecks are allows them to balance short-term needs with long-term scalability.
The best team maturity indicator is the incident and operational posture review processes. Issues will pop-up when scaling up, so how the team responds to and learns from those issues is critical. Signs of a mature team look like an organized incident remediation process, where roles amongst folks are clearly delineated. I look for leaders managing comms and coordination, while engineering is focused on mitigating the incident. Chaotic firefighting and finger-pointing is a sign of an immature team. What happens after the issue is mitigated is important: is there a blame game, or is the team writing blameless postmortems as a learning medium.
A team that learns from failure is better equipped for the future.
The Verdict
Taking all that we’ve covered so far, when I need to form a judgement I bucket my findings into three categories:
Built for scale, meaning, the system I’ve audited has scale as one of its guiding principles and can scale well with a surge of popularity/traffic.
Scalable with some effort. This means that the system is generally sound, but I’ve identified bottlenecks or areas where significant effort is required so the system scales well. Usually these are database replicas, elastic scaling (if in the cloud), improved monitoring and alerting. Fixing these requires a clear roadmap and a group of individuals/team to work on it. Typically, most of the systems I’ve worked with are in this bucket.
Fragile, will likely crumble. The system has fundamental flaws that cannot be easily fixed to scale without significant rework. This system will struggle or fail under significant traffic/popularity surge. If the system is in this shape, assuming I can, I strongly suggest to leadership to invest resources in this area. Otherwise, any money spent on marketing to bring people to the product will go down the drain once users start trickling in.
At all costs, I avoid the trap of "Complete Rewrite". As an outsider, it’s difficult to make such a damning call. Sure, there are times a complete rewrite is necessary. But they’re also very costly and risky. I assess if targeted refactoring and incremental improvements can suffice, or if the foundation is truly rotten. If I can’t assess that, then I steer clear from suggesting rewrites as they can backfire.
Liked this article? Make sure to ❤️ click the like button.
Got thoughts or feedback? Make sure to 💬 comment.
Know someone who would find this helpful? Make sure to 🔁 share this post.
Want more? Here is how I can further help you
Need technical due diligence or advising? Drop me a message on LinkedIn or at the email below.
Get one of my ebooks here.
Sign up for 1:1 mentorship, resume feedback, career strategy or an AMA session here.
Get in touch
You can find me on LinkedIn or BlueSky.
If you wish to make a request on particular topic you would like to read, you can send me an email to blog at ieftimov dot com.